刚刚,OpenAI股改完成,非营利主体更名
刚刚,OpenAI股改完成,非营利主体更名刚刚,OpenAI宣布已完成资本结构重组。这就意味着,OpenAI上市的道路已经铺平,而软银前几天刚批准的225亿美元投资,也将顺利到账。具体来说,OpenAI重组后,非营利主体(即原本的OpenAI Nonprofit)改名为OpenAI Foundation,继续掌控营利实体——
来自主题: AI资讯
11762 点击 2025-10-29 09:43
 搜索
搜索
刚刚,OpenAI宣布已完成资本结构重组。这就意味着,OpenAI上市的道路已经铺平,而软银前几天刚批准的225亿美元投资,也将顺利到账。具体来说,OpenAI重组后,非营利主体(即原本的OpenAI Nonprofit)改名为OpenAI Foundation,继续掌控营利实体——
凌晨三点,一个用户在 ChatGPT 的对话框里输入,「我已经没有办法再坚持了。」

OpenAI 发布了一份报告: AI in Japan: OpenAI’s Economic Blueprint 如何利用 AI,加速创新、增强竞争力,并推动可持续、包容性的增长

近日,有开发者发现,OpenAI 官方在 “openai-agents-js” GitHub 仓库中被提及一个新模型:GPT-5.1 mini 。“显然 GPT-5.1 mini 是真实的……”以下是即将推出的 GPT 模型可能采用的命名规则。

OpenAI距离IPO更近一步。最新消息,软银批准了对OpenAI剩余的225亿美元投资,这笔融资的条件是OpenAI要在年底前完成重组,为上市铺平道路。与此同时,奥特曼各种骚操作被曝光:他绕过投行和律师,主要依靠自己的心腹和英伟达、AMD等谈判,操盘了价值1.5万亿美元的芯片交易。

刚面世时的 Sora 有多红火,现在就有多麻烦。这个月,日本政府正式呼吁 OpenAI 在推出 Sora 2 的过程中「应避免侵犯版权」,并强调「漫画与动画角色是日本引以为傲、不可替代的文化瑰宝」。

总部位于东京的人工智能开发商Sakana AI 正与美国和日本投资者洽谈,拟以 25 亿美元的估值融资 1 亿美元,较一年前一轮融资的估值上涨 66%。参与商谈的两位知情人士透露了这一消息。

传闻许久的 OpenAI AI Agent 浏览器,如今这个靴子终于正式落地。但 AI 浏览器已经是巨头新贵正在不断涌入的赛道,OpenAI 还未正式下场,就已经有了十足的火药味:预热推文评论区最高赞的评论,就是一名用户表示自己已经卸载了 Chrome,等待 Atlas,颇有点「打扫卫生再请客」的感觉。

OpenAI新研究团队,刚刚曝光了——OpenAI for Science,致力于构建加速数学和物理领域新发现的人工智能系统。
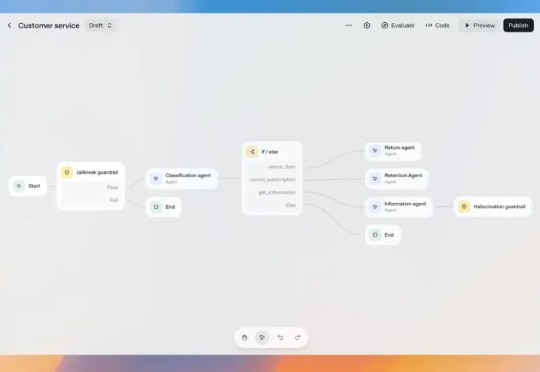
在几天前的开发者大会上,OpenAI 发布了一套面向开发者和企业的完整工具集 AgentKit。其中,可视化画布 Agent Builder 用于创建、管理和版本化多智能体工作流,通过拖拽节点的方式即可编辑工作流。